关于重编译wrf时的一些建议
通常,我们进行一些敏感性实验时,需要修改WRF自带的源代码。比如:
In this study, no specific radiation scheme available in the WRFv2.1.1 package was employed. Rather, a constant radiational cooling of
-0.5 K / day was applied at all vertical model levels. (Gall and Frank,2009)
上述一篇文献中作者就修改了WRF的辐射方案为一个固定的常数,-0.5 k $day^{-1}$,这肯定就需要修改WRF源代码中关于辐射变量相关的计算代码了。
https://github.com/wrf-model/WRF/blob/master/phys/module_radiation_driver.F
修改之后,需要重新编译WRF,使其运行时生效。那么,这就涉及到编译的速度,一般来说,完整的编译一次WRF大概需要半小时左右,这无疑是比较浪费时间的,仅仅就调整源代码的参数来说,其实完全没有必要清除所有的历史记录后编译,下面是一些建议:
如何快速的编译WRF
编译的次序
- 当您重新编译时,您是仅仅编译,还是进行了
clean-a,然后重新配置(configure),然后重新编译(compile)?
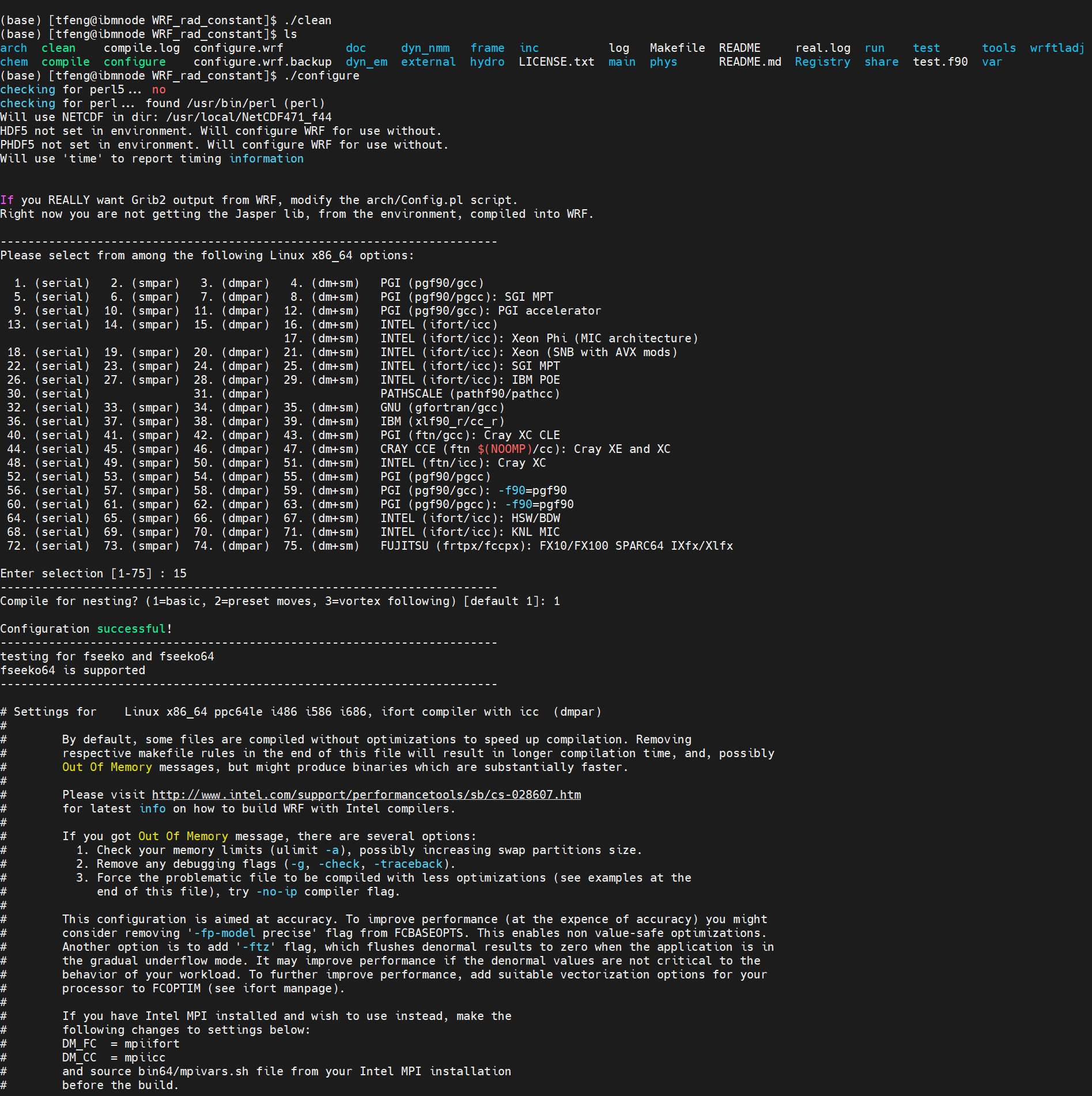
- 对于物理参数的修改,不需要clean/configure。您可以直接编译,而且通常比原始的完整编译更快。
编译器的选择
-
如果您碰巧使用的是 Intel编译器,那么编译将花费相当长的时间,即使是重新编译也是如此。
-
GNU (gfortran)编译速度快得多(而且它是一个免费的编译器)。即使您最终希望使用 Intel,为了修改代码和编译以测试准确性,切换到 GNU 也是值得的,这样您就可以进行快速编译,直到您对所有修改都满意为止。
多处理器并行编译
可以使用多个处理器进行编译。其中,最多4个处理器是一个很好的使用数字(再多的话,就会有些平稳)。在编译之前,您可以设置:
setenv J "-j 4"
(csh e.g.), or
export J="-j 4"
(bash e.g.)
因此,当你只是修改了源代码中的一些物理参数时,完全可以只进行编译,而不需要配置后在编译,亲测这样所用的时间大概在5min左右,非常快捷!
./compile em_real >& compile.log
或者将其放在后台
nohup ./compile em_real >& compile.log &
参考:
https://forum.mmm.ucar.edu/threads/quick-wrf-compilation-after-modifying-some-parameters-in-the-land-surface-model.5526/